
Verso un’AI consapevole
L'Intelligenza Artificiale non è magia (è fisica)
C'è una convinzione diffusa quando si parla di digitale: l'idea che tutto ciò che vive su uno schermo sia intrinsecamente etereo, immateriale e privo di peso. È il grande fascino del Cloud. Premi invio per chiedere a un'AI di riassumere un documento o generare un'immagine, e la risposta appare quasi per magia in pochi secondi.
Ma dietro si nasconde una realtà ben più tangibile, fatta di metallo, silicio e reti sterminate. Mentre ci si meraviglia per la fluidità di un testo generato da una macchina, si tende a ignorare che ogni singola interazione mette in moto un'infrastruttura fisica di proporzioni colossali, sostenuta da data center che lavorano a ritmi serrati.
Tutto questo genera un conto salato da pagare.
Esiste un costo economico, intimamente legato al modo in cui i modelli computazionali leggono ed elaborano le parole, ed esiste un impatto ecologico sempre più pressante. L'energia necessaria per alimentare e raffreddare questo ecosistema supera, infatti, in modo vertiginoso gli standard a cui l'informatica “tradizionale” ci aveva abituati.
Niente panico: l'AI resta uno strumento rivoluzionario fondamentale. Ma proprio per questo, l'adozione su larga scala di queste tecnologie impone un rapido cambio di mentalità verso un uso consapevole. Significa ottimizzare i prompt, ridurre gli sprechi e capire quando l'AI sia davvero la risorsa adatta o quando stiamo scomodando una tecnologia complessa per compiti risolvibili con strumenti molto più leggeri.
Come è possibile, quindi, integrare questa innovazione nel quotidiano mantenendo un equilibrio con l'etica e la sostenibilità ambientale? Il primo passo è esplorare la sala macchine.
Io che scrivo la funzione somma() in un progetto 100% vibe coding. Fa esattamente le stesse cose degli altri. Con un’architettura completamente diversa. Ovviamente.
Il cuore fisico dell’AI: l’infrastruttura invisibile
Quando si interagisce con un'applicazione basata sull'intelligenza artificiale, spesso ci si limita a immaginare un software complesso, fatto di algoritmi invisibili che fluttuano nel web. Ma il software, da solo, non va da nessuna parte senza un hardware che ne sostenga il peso: l'AI richiede un'infrastruttura fisica.
Questa base tecnologica è composta da un mix di hardware e network estremamente avanzati, ospitati all'interno di data center interamente dedicati all'intelligenza artificiale. Per far funzionare questi sistemi si utilizzano i normali chip altamente specializzati come le GPU (Graphics Processing Unit), le TPU (Tensor Processing Unit) e CPU di ultima generazione.
Per capire davvero l'entità di questa corsa agli armamenti computazionali, basta guardare ai giganti del settore tecnologico. Meta, ad esempio, sta costruendo enormi data center di tipo hyperscale, implementando nei propri server decine di migliaia di GPU , aumentando contemporaneamente in modo massiccio gli investimenti in CPU ad alte prestazioni destinate proprio all'elaborazione dell'AI (1).
Tuttavia, avere a disposizione i chip più potenti sul mercato non è sufficiente. Per sostenere il moderno ecosistema dell'intelligenza artificiale, i data center devono infatti essere supportati da reti di trasmissione dati ultra-veloci, da sistemi di stoccaggio (storage) immensi e da architetture cloud capaci di gestire moli di informazioni senza precedenti in tempo reale.
Tutta questa incredibile potenza di calcolo ha un bisogno disperato di essere alimentata e raffreddata 24 ore su 24.
L’Impronta Ecologica: oltre il digitale
Tutta questa potenza ha un costo ambientale che spesso ignoriamo. I moderni modelli di deep learning, infatti, richiedono immense risorse di calcolo e, di conseguenza, quantità di energia sbalorditive per poter funzionare.
Per rendere l'idea di questo impatto, è utile fare un paragone con un'azione quotidiana ormai data per scontata come la ricerca online. Si stima che una singola richiesta generativa arrivi a consumare circa 10 volte l’energia richiesta da una normale ricerca su Google (4). Moltiplicando questo dato per i milioni di prompt generati ogni giorno in tutto il mondo, si ottiene la reale misura del fenomeno.
Le proiezioni per il prossimo futuro, se non si interviene con un approccio consapevole, seguono questo trend di rapida crescita. Le stime di Gartner prevedono che entro il 2028 l’intelligenza artificiale arriverà a rappresentare ben il 50% delle emissioni di gas serra prodotte dall'intero settore IT (2).
Ma l'impronta ecologica non si ferma alle sole emissioni di anidride carbonica legate al consumo elettrico. Si deve infatti analizzare anche il notevole consumo idrico dei data center, un elemento fondamentale per raffreddare i server che lavorano a ciclo continuo (2, 4).
A questo si aggiunge un ulteriore problema tangibile, ovvero quello dei rifiuti elettronici. La corsa a prestazioni sempre migliori impone infatti un rapido ricambio degli hardware specializzati, i quali diventano obsoleti e vengono dismessi in tempi record.

POV: Hai comprato la RAM a febbraio 2025 a 115€ e a febbraio 2026 la vedi su Amazon a 583€.
L’economia dei Token: comprendere il valore del prompt
Oltre all'impatto ambientale, l'intelligenza artificiale porta con sé una spesa finanziaria notevole. Addestrare i grandi modelli di linguaggio, nella cosiddetta fase di training, è un'operazione che può arrivare a costare centinaia di milioni di dollari (2). Allo stesso modo, anche il semplice utilizzo in produzione, ovvero il momento in cui l'utente finale interroga l'AI, richiede il mantenimento di infrastrutture estremamente costose. Ma in che modo questa enorme spesa a monte si traduce nel costo del singolo utilizzo?
È qui che entra in gioco il concetto fondamentale di token. I token sono le unità minime di testo che il modello legge ed elabora: non coincidono esattamente con le parole, ma con frammenti di testo (parole intere, parti di parola, punteggiatura o spazi). Per avere un riferimento pratico: in inglese, per parole comuni, 1 token ≈ 1 parola. In italiano, invece, a parità di significato, servono spesso più token, perché le parole sono mediamente più lunghe e morfologicamente più ricche (6).
Nelle API commerciali, ovvero le interfacce che permettono agli sviluppatori di integrare l'AI nei propri software, le tariffe vengono calcolate proprio in base al volume di questi token. Prendendo ad esempio i costi delle API di Google Gemini, la tariffa si aggira intorno ai $2 per ogni milione di token forniti in input (5). Il calcolo finale del costo di ogni singolo prompt dipende dalla somma totale dei token elaborati, che includono sia quelli inseriti dall'utente (input) sia quelli generati come risposta dall'intelligenza artificiale (output).
Il meccanismo è lineare: un numero maggiore di token si traduce inevitabilmente in tariffe più alte e in un maggior consumo computazionale. Questo dettaglio tecnico, apparentemente riservato agli addetti ai lavori, ha in realtà un'implicazione diretta sull'uso quotidiano di chiunque interagisca con queste tecnologie. Comprendere come l'IA "legge" e "fattura" le parole è essenziale per sensibilizzare l'utente a formulare richieste (prompt) che siano estremamente concise e precise.
Eliminare i giri di parole superflui è il primo passo per un'AI sostenibile.
Ottimizzazione e strategie di mitigazione (Green AI)
Una volta compreso che ogni parola elaborata ha un peso specifico, sia sul bilancio economico che sull'ecosistema, diventa evidente la necessità di invertire la rotta. La soluzione, fortunatamente, non risiede nel tornare alla macchina da scrivere, ma nell'abbracciare best practice mirate e strategie di ottimizzazione che rientrano sotto l'ombrello della "Green AI".
Invece di assecondare la tendenza dell'industria a costruire reti neurali sempre più gigantesche e onnivore, l'ottimizzazione punta sull'efficienza intelligente.
Un primo passo fondamentale consiste nell'evitare di "reinventare la ruota" ad ogni nuovo progetto. Ripartire da zero per addestrare un nuovo modello richiede un dispendio energetico e finanziario colossale. Per questo motivo, si descrivono strategie essenziali per ridurre gli sprechi di risorse: ad esempio, è ampiamente consigliato riusare modelli pre-addestrati ricorrendo a tecniche come il transfer learning e il fine-tuning, invece di ripartire da zero (2). In pratica, si prende un'intelligenza artificiale che ha già studiato le basi e le si insegna solo la specializzazione, risparmiando mesi di calcoli intensivi.
Inoltre, non serve un’intelligenza onnisciente per compiti banali. Usare un LLM mastodontico per classificare una lista di email è paragonabile all'utilizzare un tir per andare a comprare il pane, usare un reattore nucleare per accendere una lampadina. Insomma ci siamo capiti. Il risultato si ottiene, ma lo spreco è ingiustificabile.
Al contrario, la progettazione di modelli più piccoli o specializzati (definiti task-specific) permette di ottenere le stesse funzionalità con costi ambientali molto minori (2, 3).
L'efficienza si raggiunge anche "snellendo" le architetture stesse e ottimizzando le interazioni quotidiane. Si menzionano infatti tecniche informatiche avanzate, come la compressione dei modelli, unite ad abitudini virtuose come la scrittura di prompt più brevi; queste pratiche combinate, secondo alcuni casi studio, possono ridurre i consumi fino al 90% (3). Un prompt conciso e diretto non è solo una cortesia verso il proprio portafoglio, ma un vero e proprio atto di sostenibilità ecologica.
Integrazione intelligente: l’AI non è l’unica soluzione
C'è una sorta di euforia collettiva che spinge a credere che l'intelligenza artificiale sia la panacea per ogni problema informatico. Si cerca di inserire funzionalità basate sull'AI in qualsiasi applicazione o processo aziendale, anche quando non ve n'è un bisogno reale. Tuttavia, nell'ottica di un uso realmente consapevole, è importante non delegare tutti i compiti a un modello linguistico (LLM) generico se esistono soluzioni più efficaci (7).
Ha davvero senso "svegliare" una rete neurale da miliardi di parametri per eseguire una banale operazione matematica, ordinare una lista o cercare un dato esatto e invariabile? Per compiti specifici e deterministici, la scelta migliore è usare motori di ricerca, database specialistici o calcolatrici. Solo in un secondo momento, dopo aver estratto le informazioni corrette con questi strumenti tradizionali e "leggeri", si può eventualmente arricchire il risultato sfruttando le capacità di sintesi dell’AI.
Forzare l'utilizzo di modelli generativi per ogni singola operazione non solo rischia di generare "allucinazioni" (ovvero risposte errate o inventate), ma crea un inutile sovraccarico infrastrutturale. L'integrazione intelligente richiede quindi di saper scegliere lo strumento informatico adeguato al problema, ma coinvolge anche il modo in cui i sistemi vengono progettati. Per questo motivo, si enfatizza l’uso di infrastrutture ibride (cloud+edge) per minimizzare il traffico e il carico sui data center.
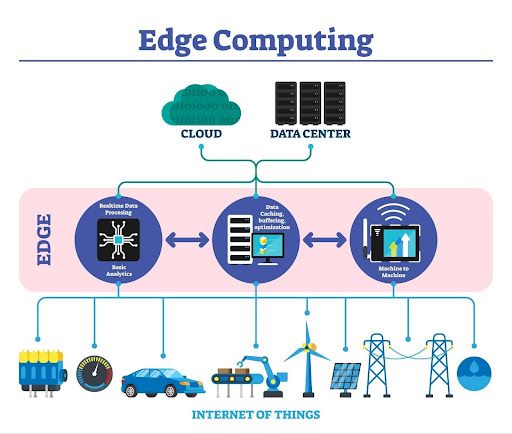
Rappresentazione del paradigma di edge computing: l’elaborazione e l’archiviazione dei dati avvengono vicino alla loro fonte, riducendo latenza e traffico verso il cloud centralizzato e migliorando le prestazioni complessive del sistema.
Invece di far viaggiare ogni singola richiesta dell'utente verso server remoti ed energivori, l'industria IT sta puntando sull'elaborazione distribuita. Tecniche avanzate come il federated learning permettono di addestrare modelli sui dispositivi locali riducendo il trasferimento di dati centrale (2). In pratica, l'elaborazione avviene in gran parte direttamente sullo smartphone o sul computer dell'utente. Questo approccio architetturale ottimizza la banda di rete, riduce i tempi di latenza e garantisce che i grandi data center vengano interpellati solo per operazioni complesse che l'hardware locale non è in grado di sostenere.
L'efficienza, in campo software, significa usare la potenza bruta dell'AI solo quando è strettamente necessaria.

Utilizzo medio dell’intelligenza artificiale.
Linee guida ed etica dell’IA: regole del gioco e responsabilità umane
C'è un aspetto psicologico affascinante quando si interagisce con un'intelligenza artificiale: ci si sente incredibilmente liberi. Sapere che dall'altra parte dello schermo non c'è un essere umano pronto a giudicare, ma un chatbot paziente e neutrale, spinge spesso ad abbassare le difese. Si fanno domande che forse per imbarazzo non si farebbero a un collega, ci si apre di più e si delegano compiti a cuor leggero, forti della certezza che la macchina non ha pregiudizi.
Tuttavia, per quanto questa interazione possa sembrare un "luogo sicuro" e privo di conseguenze, non lo è.
Proprio per evitare i rischi di uno sviluppo incontrollato, le istituzioni stanno cercando di delineare norme e raccomandazioni ufficiali. La Commissione Europea, ad esempio, ha pubblicato delle linee guida specifiche per l’uso responsabile dell’intelligenza artificiale generativa (8).
Alla base di queste direttive c'è un concetto che l'entusiasmo per la tecnologia tende spesso a far dimenticare: i modelli linguistici si limitano a calcolare, ma sono gli esseri umani a doverne rispondere. Ecco perché standard internazionali e istituzioni insistono così tanto sulla necessità di trasparenza, sull'accountability umana e su una governance etica (2, 8).
In fin dei conti, l'intelligenza artificiale non possiede una propria bussola morale per capire se un'azione sia giusta, sbagliata o eccessivamente inquinante. Sta a chi la crea, a chi la regolamenta e, in ultima istanza, a chiunque la utilizzi quotidianamente con leggerezza, garantire che rimanga un motore di sviluppo sostenibile.
Se desideri, posso fornirti una variante alternativa con un registro stilistico differente.
Scherziamo! 😀
Sitografia
- 1 Wired Italia: “Nvidia e Meta, perché l’accordo segna l'inizio di una nuova era nella corsa all'AI”
- 2 Bitrock: “Green AI: Come Integrare Etica e Sostenibilità in una Governance Consapevole”
- 3 Agenda Digitale: “L'IA consuma come 3 milioni di persone: ecco come renderla green”
- 4 Greenpeace Italia: “Il volto nascosto dell'IA”
- 5 Google AI for Developers: Gemini Developer API pricing
- 6 Google for Developers: Introduction to Large Language Models (Machine Learning Crash Course)
- 7 Apogeo Editore: “Non possiamo aspettarci di delegare l’originalità all’AI”: Sergio Sentinelli e Alessandro Placa spiegano il prompt engineering
- 8 Commissione Europea (via Biodiritto): Linee guida per l’uso responsabile dell’intelligenza artificiale generativa nella ricerca
Hai un progetto in mente?
ContattaciAutore
Gabriele Bilello
Considera la programmazione più una passione che un lavoro. È la stessa curiosità che spinge molti sviluppatori a esplorare nuovi linguaggi, framework e metodologie ogni giorno.
Per lui programmare è come un videogioco: davanti a ogni bug o requisito c’è un enigma da risolvere, una sfida da affrontare nel modo più elegante ed efficiente possibile. Ama sperimentare e provare cose nuove, soprattutto quando migliorano la developer experience e rendono il lavoro più fluido e “comodo”.
Sviluppa principalmente applicazioni web con Angular, Node.js, NestJS e Astro, ma nel tempo ha lavorato anche con PHP, MySQL, e JavaScript, senza disdegnare incursioni in altri linguaggi e tecnologie come Vue o Flutter.
Nel tempo libero gli piacciono i videogiochi e i gatti — due ottime scuole di pazienza, strategia e problem solving, qualità che tornano sorprendentemente utili anche nel codice.





